

8 ÔūŚšūŗŮŮůšÍÓ‚ Ó ÚŚűŪÓŽÓ„ŤŤ šŚšůÔŽŤÍŗŲŤŤ
28.02.2017
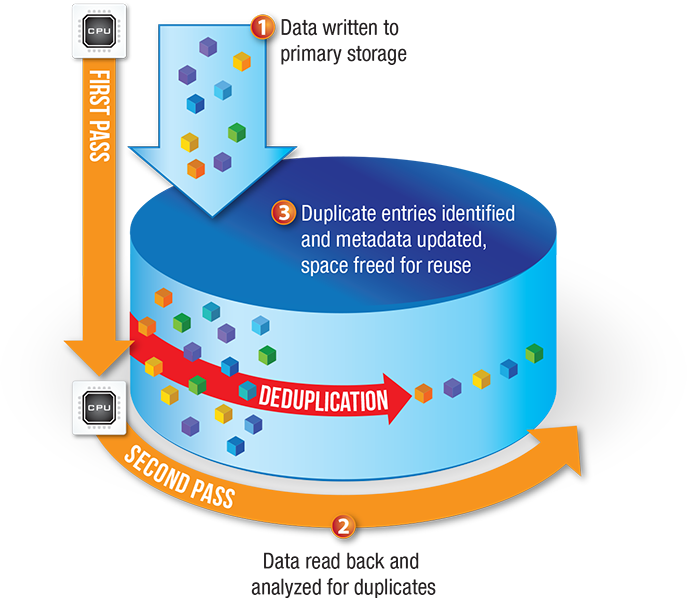
“ŚűŪÓŽÓ„Ťˇ šŚšůÔŽŤÍŗŲŤŤ ůśŚ šŗ‚ŪÓ ŤÁ‚ŚŮÚŪŗ Ť ÔūŤžŚŪˇŚÚ١ Ūŗ ÔūŗÍÚŤÍŚ ŪŚ ÔŚū‚Żť „Óš. ÕÓ ÚÓŽŁÍÓ ŤŮÔÓŽŁÁÓ‚ŗŪŤŚ ŮÓ‚ūŚžŚŪŪŻű žŗŮŮŤ‚Ó‚ ÔÓÁ‚ÓŽŤŽÓ ‚ ÔÓŽŪÓť žŚūŚ ūŗŮÍūŻÚŁ ‚ŚŮŁ ÔÓÚŚŪŲŤŗŽ żÚÓť ÚŚűŪÓŽÓ„ŤŤ. ¬ŮŚ ŮÓ‚ūŚžŚŪŪŻŚ žŗŮŮŤ‚Ż űūŗŪŚŪŤˇ šŗŪŪŻű ŤŮÔÓŽŁÁůĢÚ ŤŪŮÚūůžŚŪÚŻ šůÔŽŤÍŗŲŤŤ šŽˇ ŠÓŽŚŚ żŰŰŚÍÚŤ‚ŪÓ„Ó ŤŮÔÓŽŁÁÓ‚ŗŪŤˇ žŚŮÚŗ ‚ űūŗŪŤŽŤýŚ šŽˇ ūŗŮÔūŚšŚŽŚŪŤˇ ŗūűŤ‚ŪŻű šŗŪŪŻű. ÕÓ ŪŚ ŮŽŚšůŚÚ ŪŗšŚˇÚŁŮˇ Ūŗ ÚÓ, ųÚÓ ÔūŤžŚŪŚŪŤŚ ÚŗÍÓť ÚŚűŪÓŽÓ„ŤŤ ŤžŚŚÚ ŠŚÁ„ūŗŪŤųŪŻŚ ‚ÓÁžÓśŪÓŮÚŤ Ť ‚ ŽĢŠÓť žŗŮŮŤ‚ žÓśŪÓ ÓÔūŚšŚŽŤÚŁ ŠŚÁ„ūŗŪŤųŪŻť ÓŠķŚž ŗūűŤ‚ŤūůŚžÓť ŤŪŰÓūžŗŲŤŚť.
ÓżŰŰŤŲŤŚŪÚ ŮÓÍūŗýŚŪŤˇ šŗŪŪŻű: ŪŚÓ„ūŗŪŤųŚŪŪŻű ‚ÓÁžÓśŪÓŮÚŚť ŪŚ ŮůýŚŮÚ‚ůŚÚ.
“ŚűŪÓŽÓ„Ťˇ šŚšůÔŽŤÍŗŲŤŤ Ūŗ ŮŚ„ÓšŪˇÝŪŤť šŚŪŁ šÓŮÚůÔŪŗ šŽˇ ūŗÁŪŻű žŗŮŮŤ‚Ó‚, ÍÓÚÓūŻŚ űūŗŪˇÚ ÍŗÍ ÔūÓšůÍÚŤ‚ŪŻŚ šŗŪŪŻŚ, ÚŗÍ Ť ūŚÁŚū‚ŪŻŚ ÍÓÔŤŤ ŤŪŰÓūžŗŲŤŤ. ŌÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ šŽˇ ÚŗÍŤű žŗŮŮŤ‚Ó‚ žÓśŚÚ ŠŻÚŁ ŮÓ‚ŚūÝŚŪŪÓ ŤŪŻž. ›ÚÓ ÓÁŪŗųŗŚÚ ųÚÓ ÔÓÍŗÁŗÚŚŽŁ, ÍÓÚÓūŻť šÓŮÚŤ„ŪůÚ ‚ ūŚÁŚū‚ŪŻű žŗŮŮŤ‚ŗű ŪŚ žÓśŚÚ ŠŻÚŁ šÓŮÚŤ„ŪůÚ ‚ ÔūÓšůÍÚŤ‚ŪÓž űūŗŪŤŽŤýŚ.
ŌÓżÚÓžů, ŰÓūžŤūůˇ ÍÓŪŰŤ„ůūŗŲŤŤ šŽˇ űūŗŪŚŪŤˇ ŤŪŰÓūžŗŲŤŤ, ŗ ÚŗÍśŚ šŽˇ ūŚÝŚŪŤˇ Áŗšŗų ÓÔŚūŗÚŤ‚ŪÓ„Ó űūŗŪŚŪŤˇ šŗŪŪŻű ŮŽŚšůŚÚ ÚýŗÚŚŽŁŪÓ ÔÓšŠŤūŗÚŁ ÓŠÓūůšÓ‚ŗŪŤŚ, ůųŤÚŻ‚ŗˇ, ųÚÓ šŽˇ ūŗÁŪŻű Áŗšŗų ÔÓÍŗÁŗÚŚŽŁ ŮśŗÚŤˇ šŗŪŪŻű ŠůšŚÚ ūŗÁŪŻž.
◊ÚÓŠŻ ŤŮÍŽĢųŤÚŁ ÓÝŤŠÍŤ, ‚ÓÁžÓśŪŻŚ ÔūŤ ŤŮÔÓŽŁÁÓ‚ŗŪŤŤ żÚÓť ÚŚűŪÓŽÓ„ŤŤ, ūŗŮŮžÓÚūŤž 8 žŤŰÓ‚, ÍÓÚÓūŻŚ ÓŠŻųŪÓ ‚‚ÓšˇÚ ‚ ÁŗŠŽůśšŚŪŤŚ žŪÓ„Ťű ÔÓŽŁÁÓ‚ŗÚŚŽŚť Ť ŗšžŤŪŤŮÚūŗÚÓūÓ‚ ŮŤŮÚŚž űūŗŪŚŪŤˇ šŗŪŪŻű.
ńŗŽŚŚ ūŗŮŮžÓÚūŤž ÓŮŪÓ‚ŪŻŚ ÔūŚšūŗŮŮůšÍŤ, Ů‚ˇÁŗŪŪŻŚ Ů šŚšůÔŽŤÍŗŲŤŚť.
ŃÓŽŁÝÓť ÔÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ ÓŠŚŮÔŚųŤ‚ŗŚÚ ŠÓŽŁÝŚ ÔūŚŤžůýŚŮÚ‚ šŽˇ űūŗŪŚŪŤˇ ŤŪŰÓūžŗŲŤŤ
—ůýŚŮÚ‚ůŚÚ žŪŚŪŤŚ, ųÚÓ ŚŮŽŤ ÓšŤŪ ŤÁ ‚ŚŪšÓūÓ‚ ÔūŚšŽŗ„ŗŚÚ ÓŠÓūůšÓ‚ŗŪŤŚ Ů ÍÓżŰŰŤŲŤŚŪÚÓž šŚšůÔŽŤÍŗŲŤŤ 50:1, ÚÓ żÚÓ ŽůųÝŚ šūů„Ó„Ó ÔūŚšŽÓśŚŪŤˇ Ů ÔÓÍŗÁŗÚŚŽŚž 10:1. ¬ŚūŪÓ ŽŤ ÚŗÍÓŚ ůÚ‚ŚūśšŚŪŤŚ? ńŽˇ ÚÓ„Ó ųÚÓŠŻ ÓÔūŚšŚŽŤÚŁŮˇ Ů ÓÚ‚ŚÚÓž Ūŗ żÚÓÚ ‚ÓÔūÓŮ ŪůśŪÓ Ůūŗ‚ŪŤÚŁ ŮÓ‚ÓÍůÔŪůĢ ŮÚÓŤžÓŮÚŁ ‚ŽŗšŚŪŤˇ ŤŮÔÓŽŁÁůŚžÓ„Ó ÓŠÓūůšÓ‚ŗŪŤˇ.
ŌūÓŲŚšůūŗ šŚšůÔŽŤÍŗŲŤŤ ÓŠŚŮÔŚųŤ‚ŗŚÚ ŮÓÍūŗýŚŪŤŚ ÚūŚŠÓ‚ŗŪŤˇ Í ūŚŮůūŮŗž, ŪÓ ÍŗÍůĢ ÔÓÚŚŪŲŤŗŽŁŪůĢ żÍÓŪÓžŤĢ ÓŠķŚžŗ ÓŪŗ ŮÔÓŮÓŠŪŗ ÓŠŚŮÔŚųŤÚŁ? ŌūŤ ÔÓÍŗÁŗÚŚŽŚ 10:1 žÓśŪÓ ůžŚŪŁÝŤÚŁ ūŗÁžŚū űūŗŪŤžÓť ŤŪŰÓūžŗŲŤŤ Ūŗ 90%. ŇŮŽŤ ŤŮÔÓŽŁÁÓ‚ŗÚŁ ÍÓŪŰŤ„ůūŗŲŤŤ Ů ÔÓÍŗÁŗÚŚŽŚž 50:1, ÚÓ ů‚ŚŽŤųŤ‚ŗĢÚ١ ÚūŚŠÓ‚ŗŪŤˇ Í ūŚŮůūŮŗž Ūŗ 8% Ť ÓŠŚŮÔŚųŤ‚ŗŚÚ١ 98% żÍÓŪÓžŤŤ ÓŠķŚž. ¬ ūŚÁůŽŁÚŗÚŚ ÔÓŽůųŗŚÚ١ ÚÓŽŁÍÓ 8% ūŗÁŪŤŲŻ žŚśšů š‚ůžˇ ÍÓŪŰŤ„ůūŗŲŤˇžŤ, ÍÓÚÓūŻŚ Ūŗ ÔŚū‚Żť ‚Á„Žˇš ŮŤŽŁŪÓ ÓÚŽŤųŗŽŤŮŁ. ¬ ÚŗÍÓž ŮŽůųŗŚ žÓśŪÓ ŮšŚŽŗÚŁ ‚Ż‚ÓšŻ, ųÚÓ ųŚž ‚ŻÝŚ ÔÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ, ÚŚž žŚŪŁÝŚ ÔūŚŤžůýŚŮÚ‚ ÔÓ ůžŚŪŁÝŚŪŤĢ ÓŠķŚžŗ ŤŪŰÓūžŗŲŤŤ žÓśŪÓ ÔÓŽůųŤÚŁ. “ŗÍÓŚ ůÚ‚ŚūśšŚŪŤŚ ‚ŻűÓšŤÚ ŤÁ ÁŗÍÓŪŗ ůŠŻ‚ŗĢýŚť šÓűÓšŪÓŮÚŤ.
—ůýŚŮÚ‚ůŚÚ ųŚÚÍÓŚ ÓÔūŚšŚŽŚŪŤŚ ÚŚūžŤŪŗ šŚšůÔŽŤÍŗŲŤˇ
“ŚűŪÓŽÓ„Ťˇ šŚšůÔŽŤÍŗŲŤŤ ÓŠŚŮÔŚųŤ‚ŗŚÚ ‚ÓÁžÓśŪÓŮÚŁ ŮÓÍūŗýŚŪŤˇ ÓŠķŚžŗ űūŗŪŤžÓť ŤŪŰÓūžŗŲŤŤ ÔÓŮūŚšŮÚ‚Óž ůšŗŽŚŪŤˇ ÔÓ‚ÚÓūˇĢýŤű١ šŗŪŪŻű ŤÁ ŚšŤŪÓ„Ó ÔůŽŗ. ńŚšůÔŽŤÍŗŲŤĢ žÓśŪÓ ūŚŗŽŤÁÓ‚ŗÚŁ Ūŗ ŰŗťŽÓ‚Óž Ť ŠŽÓųŪÓž ůūÓ‚ŪŚ ŽŤŠÓ śŚ Ūŗ ůūÓ‚Ūˇű ÍÓŪÚŚŪÚŗ Ť ÔūŤŽÓśŚŪŤť. ŃÓŽŁÝÓŚ ųŤŮŽÓ ÔūŚšŽŗ„ŗŚžŻű ÔÓŽŁÁÓ‚ŗÚŚŽĢ ÔūŤŽÓśŚŪŤť ‚žŚŮÚŚ Ů šŚšůÔŽŤÍŗŲŤŚť ŮÓųŚÚŗĢÚ Ť ÍÓžÔūŚŮŮŤĢ, ųÚÓ ÔÓÁ‚ÓŽˇŚÚ ŚýŚ ŠÓŽŁÝŚ ŮÓÍūŗÚŤÚŁ ÓŠķŚž űūŗŪŤžŻű šŗŪŪŻű. ŮÓśŗŽŚŪŤĢ, Ūŗ ŮŚ„ÓšŪˇÝŪŤť šŚŪŁ ŪŚ ŮůýŚŮÚ‚ůŚÚ ŚšŤŪÓ„Ó ÓÔūŚšŚŽŚŪŤˇ, ųÚÓ ŤžŚŪŪÓ ÔūŚšŮÚŗ‚ŽˇŚÚ ŮÓŠÓť ÚŚűŪÓŽÓ„Ťˇ šŚšůÔŽŤÍŗŲŤŤ Ť ÍŗÍŤŚ ŗŽ„ÓūŤÚžŻ ůžŚŪŁÝŚŪŤˇ ÓŠķŚžŗ ŤŪŰÓūžŗŲŤŤ ÔÓšűÓšˇÚ ÔÓš żÚÓÚ ŤŪŰÓūžŗŲŤÓŪŪŻť ŤŪŮÚūůžŚŪÚ. ¬ ÚÓ śŚ ‚ūŚžˇ šŽˇ ÍÓŪŚųŪÓ„Ó ÔÓŽŁÁÓ‚ŗÚŚŽˇ ‚ŗśŪÓ, ÍŗÍŤž ŤžŚŪŪÓ ŮÔÓŮÓŠÓž ÓŪ ŮžÓśŚÚ ŮżÍÓŪÓžŤÚŁ ŤžŚĢýŤŚŮˇ šŤŮÍÓ‚ŻŚ ūŚŮůūŮŻ šŽˇ űūŗŪŚŪŤˇ ŤŪŰÓūžŗŲŤŤ.
–ŗŮŮžÓÚūŤž ÍŗÍŤŚ ‚ŗūŤŗŪÚŻ ŮÓÍūŗýŚŪŤˇ šŗŪŪŻű ‚ žŗŮŮŤ‚ŗű žÓ„ůÚ ŤŮÔÓŽŁÁÓ‚ŗڣ١ ÍÓŪŚųŪŻžŤ ÔÓŽŁÁÓ‚ŗÚŚŽˇžŤ Ūŗ ÔūŤžŚūŚ žŗŮŮŤ‚ŗ ÓÚ HP 3PAR. ńŽˇ ūŗŠÓÚŻ Ů żÚŤžŤ žŗŮŮŤ‚ŗžŤ ūŗÁūŗŠÓÚŗŪ ŮÔŚŲŤŗŽŁŪŻť ÍÓžÔŽŚÍŮ HPE 3PAR Thin Technologies, ÍÓÚÓūŻť ‚ÍŽĢųŗŚÚ ‚ Ů‚Óť ŮÓŮÚŗ‚ 4 žŚűŗŪŤÁžŗ.
- Thin Provisioning Ė żÚÓÚ žŚűŗŪŤÁž ÓŮŪÓ‚ŗŪ Ūŗ ŤŮÔÓŽŁÁÓ‚ŗŪŤŤ ‚ŤūÚůŗŽŤÁŗŲŤŤ šŤŮÍÓ‚Ó„Ó ÔūÓŮÚūŗŪŮÚ‚ŗ, ųÚÓ ÔÓÁ‚ÓŽˇŚÚ, ÔūŤ ÓŮ‚ÓŠÓśšŚŪŤŤ ūŚŮůūŮÓ‚ žŗŮŮŤ‚ŗ, ŪŚ ‚ŻÔÓŽŪˇÚŁ ūŚ‚ŤÁŤĢ, ŗ ÓŮ‚ÓŠÓšŤ‚ÝŚŚŮˇ ŠŽÓÍŤ ŮūŗÁů ÔūŤžŚŪˇÚŁ šŽˇ ŪŗÔÓŽŪŚŪŤˇ ŪÓ‚Óť ŤŪŰÓūžŗŲŤŚť.
- Thin Conversion Ė ŠŽŗ„Óšŗūˇ żÚÓžů žŚűŗŪŤÁžů žÓśŪÓ ÔŚūŚ‚ÓšŤÚŁ ‚ ūŚŗŽŁŪÓž ‚ūŚžŚŪŤ ÚÓžŗ ŮÓ ŮÚŗūŻű žŗŮŮŤ‚Ó‚ ŤŪŰÓūžŗŲŤŤ ‚ ŪÓ‚ŻŚ Ů ÔÓŮŽŚšůĢýŤž ŮÓÍūŗýŚŪŤŚž ÓŠķŚžŗ ÚÓžÓ‚ Ūŗ ŲŚŽŚ‚Óž ůŮÚūÓťŮÚ‚Ś
- Thin Persistence Ť Thin Copy Reclamation Ė Ů ÔÓžÓýŁĢ żÚŤű ūŚŮůūŮÓ‚ žŗŮŮŤ‚ Ūŗ „ūŗŪůŽˇūŪÓž ůūÓ‚ŪŚ ÔÓŪŤžŗŚÚ ŰůŪÍŲŤÓŪŤūÓ‚ŗŪŤŚ ŤÁ‚ŚŮÚŪŻű ŰŗťŽÓ‚Żű ŮŤŮÚŚž Ť „ŤÔŚū‚ŤÁÓūÓ‚ ÔūŤ ůšŗŽŚŪŤŤ ŰŗťŽÓ‚. ¬ ÚŗÍÓž ŮŽůųŗŚ ÓŮ‚ÓŠÓśšŗĢýŤŚŮˇ ŠŽÓÍŤ ÔŚūŚ‚ÓšˇÚ١ ‚ ÔůŽ Ů‚ÓŠÓšŪŻű ūŚŮůūŮÓ‚, ÍÓÚÓūŻŚ šÓŮÚůÔŪŻ Í ÔÓŮŽŚšůĢýŚžů ŤŮÔÓŽŁÁÓ‚ŗŪŤĢ.
- Thin Deduplication Ė ÚŗÍŗˇ žŚÚÓšŤÍŗ ÔÓÁ‚ÓŽˇŚÚ ÔūŤžŚŪˇÚŁ ÚŚűŪÓŽÓ„ŤĢ šŚšůÔŽŤÍŗŲŤŤ ‚ ÔūÓšůÍÚŤ‚ŪŻű žŗŮŮŤ‚ŗű ‚ ūŚśŤžŚ ūŚŗŽŁŪÓ„Ó ‚ūŚžŚŪŤ, ŤŮÍŽĢųŗˇ ŮŪŤśŚŪŤŚ ÓŠýŚť ÔūÓŤÁ‚ÓšŤÚŚŽŁŪÓŮÚŤ űūŗŪŤŽŤý.
ÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ šŽˇ ÓŮŪÓ‚ŪÓ„Ó žŗŮŮŤ‚ŗ ÚŗÍÓť śŚ ÍŗÍ Ť šŽˇ žŗŮŮŤ‚ŗ Ů ūŚÁŚū‚ŪŻžŤ šŗŪŪŻžŤ
–ŗÁūŗŠÓÚųŤÍŗžŤ ŮŤŮÚŚž űūŗŪŚŪŤˇ ŤŪŰÓūžŗŲŤŤ ÔūŗÍÚŤÍůŚÚ١ ÔūŤžŚŪŚŪŤŚ ūŗÁŽŤųŪŻű ŗŽ„ÓūŤÚžÓ‚ šŚšůÔŽŤÍŗŲŤŤ. ÕŚÍÓÚÓūŻŚ ŤÁ ÚŗÍŤű ŗŽ„ÓūŤÚžÓ‚ ŪůśšŗĢÚ١ ‚ ŠÓŽŁÝŤű ūŚŮůūŮŗű ŲŚŪÚūŗŽŁŪÓ„Ó ÔūÓŲŚŮŮÓūŗ, ųŚž ÓŮÚŗŽŁŪŻŚ. —ŽŚšÓ‚ŗÚŚŽŁŪÓ, ÔÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ žÓśŚÚ ‚ŗūŁŤūÓ‚ŗڣ١ ‚ šÓŮÚŗÚÓųŪÓ ŠÓŽŁÝÓž ŤŪÚŚū‚ŗŽŚ ÁŪŗųŚŪŤť.
ÕÓ, žŗÍŮŤžŗŽŁŪÓ ‚ŽŤˇŚÚ Ūŗ ÚÓ, ÍŗÍÓť ÔÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ ŠůšŚÚ šŽˇ ÍÓŪÍūŚÚŪÓ„Ó žŗŮŮŤ‚ŗ, ÍÓŽŤųŚŮÚ‚Ó ÔÓ‚ÚÓūˇĢýŤű١ šŗŪŪŻű. ŌÓżÚÓžů ŮŤŮÚŚžŻ ūŚÁŚū‚ŪÓ„Ó ŗūűŤ‚ŤūÓ‚ŗŪŤˇ, ÍÓÚÓūŻŚ žÓ„ůÚ ŤžŚÚŁ ‚ Ů‚ÓŚž ŮÓŮÚŗ‚Ś ŪŚŮÍÓŽŁÍÓ ÓšŤŪŗÍÓ‚Żű ÍÓÔŤť ÓšŪÓť Ť ÚÓť śŚ ŤŪŰÓūžŗŲŤŤ, ŠůšůÚ űŗūŗÍÚŚūŤÁÓ‚ŗڣ١ ‚ŻŮÓÍŤžŤ ÍÓżŰŰŤŲŤŚŪÚŗžŤ šŚšůÔŽŤÍŗŲŤŤ. ¬ ÚÓ śŚ ‚ūŚžˇ šŽˇ ÓÔŚūŗÚŤ‚ŪŻű ŮŤŮÚŚž űūŗŪŚŪŤˇ ŤŪŰÓūžŗŲŤŤ, ÍÓÚÓūŻŚ ‚ŽŗšŚĢÚ ŰŗÍÚŤųŚŮÍŤ ůŪŤÍŗŽŁŪŻž ŪŗŠÓūÓž šŗŪŪŻű, ÔÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ ŠůšŚÚ žŤŪŤžŗŽŚŪ. ŇŮŽŤ Ūŗ ÔūÓšůÍÚŤ‚ŪÓž žŗŮŮŤ‚Ś űūŗŪŤÚ١ ŪŚŮÍÓŽŁÍÓ ÍÓÔŤť ÓÔŚūŗÚŤ‚ŪÓť ŤŪŰÓūžŗŲŤŚť, ÚÓ żÚÓ žÓśŚÚ ÔūŤ‚ÓšŤÚŁ Í ů‚ŚŽŤųŚŪŤĢ ÍÓżŰŰŤŲŤŚŪÚŗ šŚšůÔŽŤÍŗŲŤŤ, ÚŗÍ ÍŗÍ ŠůšůÚ ÁŗšŚťŮÚ‚Ó‚ŗڣ١ žŚűŗŪŤÁžŻ ŮÓÍūŗýŚŪŤˇ žŚŮÚŗ űūŗŪŚŪŤˇ šŗŪŪŻű.
ŌÓżÚÓžů ŤžŚÚŁ šŽˇ žŗŮŮŤ‚ŗ ÓÔŚūŗÚŤ‚ŪŻű šŗŪŪŻű ÔÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ 5:1 ÚŗÍśŚ űÓūÓÝÓ, ÍŗÍ Ť ‚ŽŗšŚÚŁ ÍÓżŰŰŤŲŤŚŪÚÓž 40:1 ŤŽŤ 30:1 šŽˇ ŮŤŮÚŚž ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ.
ŇŮŽŤ šŽˇ ÔūŤžŚūŗ ‚ÁˇÚŁ ÔūÓšůÍŲŤĢ ÍÓžÔŗŪŤŤ HPE Ė žŗŮŮŤ‚ HPE 3PAR, ÚÓ šŽˇ ÓÔŚūŗÚŤ‚ŪÓ„Ó űūŗŪŚŪŤˇ šŗŪŪŻű ÔÓŤŮÍ ŮűÓśŤű ÔÓŮŽŚšÓ‚ŗÚŚŽŁŪÓŮÚŚť ÓŠŚŮÔŚųŤ‚ŗŚÚ١ Ūŗ ŽŚÚů Ů ÔÓžÓýŁĢ ŮÔŚŲŤŗŽŁŪÓť žŤÍūÓŮűŚžŻ ASIC, ÍÓÚÓūŗˇ ůŮÚŗŪÓ‚ŽŚŪŗ ‚ ÍŗśšÓž ŤÁ ÍÓŪÚūÓŽŽŚūÓ‚ žŗŮŮŤ‚ŗ. ŃŽŗ„Óšŗūˇ żÚÓžů ŮůýŚŮÚ‚ŚŪŪÓ ūŗÁ„ūůśŗĢÚ١ ŲŚŪÚūŗŽŁŪŻŚ ÔūÓŲŚŮŮÓūŻ žŗŮŮŤ‚ŗ Ů ÚÓť ŲŚŽŁĢ, ųÚÓŠŻ ÁŗšŚťŮÚ‚Ó‚ŗÚŁ Ťű ÔÓÚŚŪŲŤŗŽ šŽˇ ŠÓŽŚŚ ‚ŗśŪŻű Áŗšŗų. ūÓžŚ żÚÓ„Ó, ÔÓūÚŰŚŽŁ HP šŽˇ Ů‚ÓŤű žŗŮŮŤ‚Ó‚ ÔūŚšŽŗ„ŗŚÚ Ť ŗÔÔŗūŗÚŪŻŚ ÍÓžÔŽŚÍŮŻ ūŚÁŚū‚ŪÓ„Ó ŗūűŤ‚ŤūÓ‚ŗŪŤˇ šŗŪŪŻű Ů ÔÓššŚūśÍÓť ÓŪŽŗťŪ šŚšůÔŽŤÍŗŲŤŤ Ūŗ ůūÓ‚Ūˇű ŠŽÓÍÓ‚ ÔŚūŚžŚŪŪÓť šŽŤŪŻ. ŃŽŗ„Óšŗūˇ żÚÓžů ůÔūÓýŗŚÚ١ Ť ůŮÍÓūˇŚÚ ÔūÓŲŚŮŮ ÔŚūŚŪÓŮŗ ŤŪŰÓūžŗŲŤŤ ÔūÓšůÍÚŤ‚ŪŻű žŗŮŮŤ‚Ó‚ Ūŗ ŮŤŮÚŚžů ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ ŠŚÁ ÔūŤžŚŪŚŪŤˇ ŮÔŚŲŤŗŽŁŪÓ„Ó ŮÓŰÚŗ ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ Ť ŠŚÁ ‚ŻšŚŽŚŪŤˇ ŮŚū‚Śūŗ šŽˇ ŠżÍŗÔÓ‚.
¬ŮŚ šŗŪŪŻŚ ˇ‚ŽˇĢÚ١ ÓšŤŪŗÍÓ‚ŻžŤ
“ůÚ ŪŚ šÓŽśŪÓ ÓŮÚŗ‚ŗڣ١ ŪŤÍŗÍŤű ŮÓžŪŚŪŤť Ė ‚ŮŚ šŗŪŪŻŚ ˇ‚ŽˇĢÚ١ ūŗÁŪŻžŤ. ńŗśŚ ÚŚ šŗŪŪŻŚ, ÍÓÚÓūŻŚ ÔÓŽůųŚŪŻ ÓšŪÓ„Ó Ť ÚÓ„Ó śŚ ÔūŤŽÓśŚŪŤˇ šŽˇ ūŗÁŽŤųŪŻű ůŮŽÓ‚Ťť ŠůšůÚ ÓÚŽŤųŗڣ١ ÍÓżŰŰŤŲŤŚŪÚŗžŤ šŚšůÔŽŤÍŗŲŤŤ ‚ ůŮŽÓ‚Ťˇű ÓšŪÓ„Ó Ť ÚÓ„Ó śŚ žŗŮŮŤ‚ŗ. ›ÚÓ Ů‚ˇÁŗŪÓ Ů ÚŚž, ųÚÓ ÔÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ šŽˇ ÍÓŪÍūŚÚŪŻű šŗŪŪŻű ŠůšŚÚ Áŗ‚ŤŮŚÚŁ ÓÚ ūŗÁŽŤųŪŻű ŰŗÍÚÓūÓ‚, ŮūŚšŤ ÍÓÚÓūŻű ŮŽŚšůĢýŤŚ:
- ÚŤÔ šŗŪŪŻű Ė šŗŪŪŻŚ, ÍÓÚÓūŻŚ ÔūÓÝŽŤ ÔūÓ„ūŗžžŪÓŚ ŮśŗÚŤŚ, žŚÚŗšŗŪŪŻŚ, ‚ŤšŚÓÔÓÚÓÍŤ Ť ÁŗÝŤŰūÓ‚ŗŪŪŗˇ ŤŪŰÓūžŗŲŤˇ ‚ŮŚ„šŗ ÓÚŽŤųŗĢÚ١ ŪŚŠÓŽŁÝŤž ÍÓżŰŰŤŲŤŚŪÚÓž šŚšůÔŽŤÍŗŲŤŤ ŤŽŤ ‚Ó‚ŮŚ ŪŚ ÔÓššŗĢÚ١ ŮśŗÚŤĢ;
- ŮÚŚÔŚŪŁ ‚ÓÁžÓśŪÓť ŤÁžŚŪˇŚžÓŮÚŤ šŗŪŪŻű Ė ųŚž ŠůšŚÚ ‚ŻÝŚ ÓŠķŚž ŚśŚšŪŚ‚ŪŻű ŤÁžŚŪŚŪŤť ŤŪŰÓūžŗŲŤŤ Ūŗ ŰŗťŽÓ‚Óž ŤŽŤ ŠŽÓųŪÓž ůūÓ‚ŪŚ, ÚŚž žŚŪŁÝŚ ŠůšŚÚ ÍÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ. őŮÓŠŚŪŪÓ żÚÓ ŗÍÚůŗŽŁŪÓ šŽˇ ŮŤŮÚŚž ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ šŗŪŪŻű;
- ŮūÓÍ űūŗŪŚŪŤˇ Ė ųŚž ŠÓŽŁÝŚ ŤšŚŪÚŤųŪŻű ÍÓÔŤť ŤžŚŚÚ١ ‚ űūŗŪŤŽŤýŚ, ÚŚž ŠÓŽŁÝŚ ŠůšŚÚ ÍÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ ÚŗÍŤű šŗŪŪŻű;
- ÔÓŽŤÚŤÍŗ ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ Ė ŚŮŽŤ ŮÓÁšŗ‚ŗÚŁ šŪŚ‚ŪŻŚ ÔÓŽŪŻŚ ÍÓÔŤŤ ‚žŚŮÚÓ ŤŮÔÓŽŁÁÓ‚ŗŪŤˇ ŤŪÍūŚžŚŪÚŪŻű ŤŽŤ šŤŰŰŚūŚŪŲŤŗŽŁŪŻű ŠżÍŗÔÓ‚, ÚÓ žÓśŪÓ ÔÓŽůųŤÚŁ ŮůýŚŮÚ‚ŚŪŪÓ ‚ŻŮÝŤť ÍÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ.
ŌūÓ‚ŚšŚŪŤŚ „ūůÔÔŤūÓ‚ÍŤ ŪŚŮ‚ˇÁŗŪŪŻű ÚŤÔÓ‚ šŗŪŪŻű ÓŠŚŮÔŚųŤ‚ŗŚÚ ūÓŮÚ ůūÓ‚Ūˇ šŚšůÔŽŤÍŗŲŤŤ
¬ ÚŚÓūŤŤ žÓśŪÓ ŮžŚÝŤ‚ŗÚŁ ūŗÁŪŻŚ ÚŤÔŻ ŤŪŰÓūžŗŲŤŤ ‚ ÓšŪÓž ÔůŽŚ šŽˇ šŚšůÔŽŤÍŗŲŤŤ. ¬ÓÁŪŤÍŗŚÚ ŽÓśŪÓŚ ÓýůýŚŪŤŚ, ųÚÓ ŤžŚˇ Ó„ūÓžŪŻť ŪŗŠÓū šŗŪŪŻű, ŠůšŚÚ ŠÓŽŁÝŗˇ ‚ŚūÓˇÚŪÓŮÚŁ ŪŗűÓśšŚŪŤˇ ‚ ŪŚž ůśŚ ÁŗÔŤŮŗŪŪŻű ūŗŪŚŚ ŤŪŰÓūžŗŲŤÓŪŪŻű ŠŽÓÍÓ‚. Õŗ ÔūŗÍÚŤÍŚ ‚ŮŚ ÓŠŮÚÓŤÚ ÔÓ-šūů„Óžů. ńŚŽÓ ‚ ÚÓž, ųÚÓ ŪŚ Ů‚ˇÁŗŪŪŻŚ ÚŤÔŻ šŗŪŪŻű, ŪŗÔūŤžŚū žŚśšů ŠŗÁÓť šŗŪŪŻű Ť Exchange, ‚ŽŗšŚĢÚ ūŗÁŪŻžŤ ŰÓūžŗÚŗžŤ. ńŗśŚ ŚŮŽŤ ÓŪŤ Ť ŤžŚĢÚ ÓšŤŪ Ť ÚÓÚ śŚ ŪŗŠÓū ŤŪŰÓūžŗŲŤŤ, ÚÓ ŠůšůÚ ÍŗÁŗڣ١ ūŗÁŪŻžŤ. ¬ ÚŗÍÓž ŮŽůųŗŚ ÔůŽ ÔÓŮÚÓˇŪŪÓ ŠůšŚÚ ŪŗūŗŮÚŗÚŁ, ůŮŽÓśŪˇÚŁŮˇ Ť ÚūŚŠÓ‚ŗÚŁ ŠÓŽŁÝŚ ‚ūŚžŚŪŤ šŽˇ ÔÓŤŮÍŗ šůŠŽŤūůĢýŚťŮˇ ÔÓŮŽŚšÓ‚ŗÚŚŽŁŪÓŮÚŤ šŗŪŪŻű. ňůųÝŚť ÔūŗÍÚŤÍÓť šŽˇ ÔūÓ‚ŚšŚŪŤˇ šŚšůÔŽŤÍŗŲŤŤ ‚ ÚŗÍÓž ŮŽůųŗŚ ˇ‚ŽˇŚÚ١ ūŗÁšŚŽŚŪŤˇ ÔůŽÓ‚ ÔÓ ÚŤÔů šŗŪŪŻű.
ńŽˇ ÔūŤžŚūŗ, ŚŮŽŤ ÔūÓ‚ÓšŤÚŁ ÔūÓŲŚšůūů šŚšůÔŽŤÍŗŲŤŤ šŽˇ ÓšŪÓť ‚ŤūÚůŗŽŁŪÓť žŗÝŤŪŻ, ÚÓ žÓśŪÓ ÔÓŽůųŤÚŁ ŪŚÍÓÚÓūŻť ÔÓÍŗÁŗÚŚŽŁ šŚšůÔŽŤÍŗŲŤŤ. ŇŮŽŤ śŚ ŮÓÁšŗÚŁ ŪŚŮÍÓŽŁÍÓ ÍÓÔŤť ÚŗÍÓť ‚ŤūÚůŗŽŁŪÓť žŗÝŤŪŻ Ť ÔÓŮŽŚ żÚÓ„Ó ÔūÓ‚ŚŮÚŤ šŚšůÔŽŤÍŗŲŤĢ Ūŗ żÚÓž ÔůŽŚ, ÚÓ ÍÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ ŮůýŚŮÚ‚ŚŪŪÓ ‚ŻūŗŮÚŚÚ. ŇŮŽŤ śŚ ŪŚŮÍÓŽŁÍÓ ‚ŤūÚůŗŽŁŪŻű žŗÝŤŪ Ů„ūůÔÔŤūÓ‚ŗÚŁ ÔÓ ÚŤÔů ÔūŤŽÓśŚŪŤť, ŗ ÔÓÚÓž ŮÓÁšŗÚŁ ŪŚŮÍÓŽŁÍÓ ÍÓÔŤť ÚŗÍŤű žŗÝŤŪ, ÚÓ ÍÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ ‚ŻūŗŮÚŚÚ ŚýŚ ŠÓŽŁÝŚ.
ŌŚū‚ÓŚ ūŚÁŚū‚ŪÓŚ ÍÓÔŤūÓ‚ŗŪŤŚ žÓśŚÚ ÔÓÍŗÁŗÚŁ ‚ŚŽŤųŤŪů ÓśŤšŗŚžÓ„Ó ÍÓżŰŰŤŲŤŚŪÚŗ šŚšůŠŽŤÍŗŲŤŤ
›ÚÓ ÓÝŤŠÓųŪÓŚ žŪŚŪŤŚ Ė ÓŪÓ ÔūÓˇ‚ŽˇŚÚ١ ÔūŤ Ůūŗ‚ŪŚŪŤŤ ‚ŚŽŤųŤŪŻ ÍÓżŰŰŤŲŤŚŪÚŗ šŚšůÔŽŤÍŗŲŤŤ Ūŗ ÓŮŪÓ‚ŪÓž žŗŮŮŤ‚Ś űūŗŪŚŪŤŚ šŗŪŪŻű Ť Ūŗ ŮŤŮÚŚžŚ ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ ŤŪŰÓūžŗŲŤŤ. ŇŮŽŤ űūŗŪŤÚŁ ÚÓŽŁÍÓ ÓšŪů ÍÓÔŤĢ ŗūűŤ‚ŪŻű šŗŪŪŻű, ÚÓ žÓśŪÓ ÔÓŽůųŤÚŁ ŪŚÍÓÚÓūŻť ÍÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ, ÍÓÚÓūŻť ŠůšŚÚ ŠÓŽŁÝŚ ŚšŤŪŤŲŻ. Ň„Ó ÁŪŗųŚŪŤŚ ŮžÓśŚÚ ‚ŻūŗŮÚŤ ‚ ÚÓž ŮŽůųŗŚ, ŚŮŽŤ ŠůšŚÚ ů‚ŚŽŤųŚŪÓ ųŤŮŽÓ ÍÓÔŤť ÚŗÍÓť ūŚÁŚū‚ŪÓť ŤŪŰÓūžŗŲŤŤ ‚ ÚŚÍůýŚť ŠŗÁŚ šŗŪŪŻű. ¬ŻÔÓŽŪŚŪŤŚ ÓšŪÓ„Ó ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ ÔÓÍŗÁŻ‚ŗŚÚ ÓÔūŚšŚŽŚŪŪůĢ šŚšůÔŽŤÍŗŲŤĢ, ÍÓÚÓūŗˇ ˇ‚ŽˇŚÚ١ ÓųŚŪŁ ÔūŤŠŽŤÁŤÚŚŽŁŪÓť, ÔÓŮÍÓŽŁÍů ŠÓŽŁÝŗˇ żÍÓŪÓžŤˇ šÓŮÚŤ„ŗŚÚ١ ‚ ÔÓŮŽŚšŮÚ‚ŤŤ ÔÓŮūŚšŮÚ‚Óž ŮśŗÚŤˇ šŗŪŪŻű. ŗÍ ÚÓŽŁÍÓ ‚ ÔůŽŚ ÔÓˇ‚ŤÚ١ ŠÓŽŁÝÓŚ ųŤŮŽÓ ÍÓÔŤť ÓšŤŪŗÍÓ‚Żű šŗŪŪŻű, ÍÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ ŮůýŚŮÚ‚ŚŪŪÓ ‚ŻūŗŮÚŚÚ.
ÕŚ‚ÓÁžÓśŪÓ ů‚ŚŽŤųŤÚŁ ůūÓ‚ŚŪŁ šŚšůÔŽŤÍŗŲŤŤ.
ňÓśŪŻž ˇ‚ŽˇŚÚ١ žŪŚŪŤŚ, ųÚÓ ŪŚ ŮůýŚŮÚ‚ůŚÚ ‚ÓÁžÓśŪÓŮÚŤ ŤŮÍůŮŮÚ‚ŚŪŪÓ„Ó ŪŗūŗýŤ‚ŗŪŤˇ ÍÓżŰŰŤŲŤŚŪÚŗ šŚšůÔŽŤÍŗŲŤŤ. ¬ÓÔūÓŮ ‚ÓÁŪŤÍŗŚÚ ‚ šūů„Óž Ė šŽˇ ųŚ„Ó żÚÓ ŪůśŪÓ. ŇŮŽŤ šŽˇ ÓÚÓŠūŗśŚŪŤˇ ÍŗÍŤű-ÚÓ ÓŮÓŠŚŪŪŻű žŗūÍŚÚŤŪ„Ó‚Żű ÔÓÍŗÁŗÚŚŽŚť, ÚÓ żÚÓ ÓšŪÓ, ŗ ŚŮŽŤ šŽˇ ŮÓÁšŗŪŤˇ żŰŰŚÍÚŤ‚ŪÓť ŮŤŮÚŚžŻ ūŚÁŚū‚ŤūÓ‚ŗŪŤˇ, ÚÓ żÚÓ ŮÓ‚ŮŚž šūů„ŗˇ ūŚŗŽŁŪÓŮÚŁ. ŌÓŽůųŤÚŁ ŮŤŪÚŚÚŤųŚŮÍŤť žŗÍŮŤžŗŽŁŪŻť ÍÓżŰŰŤŲŤŚŪÚ šŚšůÔŽŤÍŗŲŤŤ šÓŮÚŗÚÓųŪÓ ÔūÓŮÚÓ Ė šŽˇ żÚÓť ŲŚŽŤ ŮŽŚšůŚÚ űūŗŪŤÚŁ ‚ žŗŮŮŤ‚Ś ÍŗÍ žÓśŪÓ ŠÓŽŁÝŚ ÍÓÔŤť ÓšŤŪŗÍÓ‚Żű šŗŪŪŻű. ŇŮÚŚŮÚ‚ŚŪŪÓ, żÚÓ ů‚ŚŽŤųŤÚ ÓŠķŚž űūŗŪŤžÓť ŤŪŰÓūžŗŲŤŤ, ŪÓ ÍÓżŰŰŤŲŤŚŪÚ šůÔŽŤÍŗŲŤŤ žÓśŚÚ ‚ ÚŗÍÓž ŮŽůųŗŚ ÔūŤŪŤžŗÚŁ ÓųŚŪŁ ŠÓŽŁÝŤŚ ÁŪŗųŚŪŤˇ. ›ÚÓ žÓśŚÚ żŰŰŚÍÚŤ‚ŪÓ ŤŮÔÓŽŁÁÓ‚ŗڣ١ ‚ žŗūÍŚÚŤŪ„Ó‚Żű ŲŚŽˇű, ŪÓ ŚŮŽŤ śŚ „Ó‚ÓūŤÚŁ ÓŠ żŰŰŚÍÚŤ‚ŪÓŮÚŤ ūŗŠÓÚŻ űūŗŪŤŽŤýŗ, ÚÓ ÚŗÍŤŚ ŤŮÍůŮŮÚ‚ŚŪŪÓ Áŗ‚ŻÝŚŪŪŻŚ ÍÓżŰŰŤŲŤŚŪÚŻ šŚšůÔŽŤÍŗŲŤŤ ŪŤÍŗÍÓť ÔÓŽŁÁŻ ŪŚ šŗĢÚ.
őÚŮůÚŮÚ‚ůŚÚ ‚ÓÁžÓśŪÓŮÚŁ ÔūÓ„ŪÓÁŤūÓ‚ŗŪŤˇ ‚ŚŽŤųŤŪŻ ÍÓżŰŰŤŲŤŚŪÚŗ šŚšůÔŽŤÍŗŲŤŤ
ŃÓŽŁÝŤŪŮÚ‚Ó ÔūÓŤÁ‚ÓšŤÚŚŽŚť ŮŤŮÚŚž ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ ÔūŚšÓŮÚŗ‚ŽˇĢÚ Ů‚ÓŤž ÍŽŤŚŪÚŗž ŮÔŚŲŤŗŽŁŪŻŚ ůÚŤŽŤÚŻ šŽˇ ūŗŠÓÚŻ Ů žŗŮŮŤ‚ŗžŤ Ť ŮŤŮÚŚžŗžŤ ūŚÁŚū‚ŪÓ„Ó űūŗŪŚŪŤˇ ŤŪŰÓūžŗŲŤŤ. ŃŽŗ„Óšŗūˇ żÚŤž ŤŪŮÚūůžŚŪÚÓž ÔÓˇ‚ŽˇŚÚ١ ‚ÓÁžÓśŪÓŮÚŁ ÔÓŽůųŚŪŤˇ ŤŪŰÓūžŗŲŤŤ Ó ÚŤÔŚ šŗŪŪŻű, ÔÓŽŤÚŤÍŚ ūŚÁŚū‚ŪÓ„Ó ÍÓÔŤūÓ‚ŗŪŤˇ, ŗ ÚŗÍśŚ ŮūÓÍŗű űūŗŪŚŪŤˇ ŤŪŰÓūžŗŲŤŤ. — ÔÓžÓýŁĢ ÚŗÍŤű ůÚŤŽŤÚ žÓśŪÓ ÔÓŽůųŤÚŁ ÓÔūŚšŚŽŚŪŪŻŚ šŗŪŪŻŚ Ó ‚ŚŽŤųŤŪŚ ÓśŤšŗŚžÓ„Ó ÍÓżŰŰŤŲŤŚŪÚŗ šŚšůŠŽŤÍŗŲŤŤ. ÕÓ žŗÍŮŤžŗŽŁŪÓ ÚÓųŪŻť ÔūÓ„ŪÓÁ ÔÓ ÁŪŗųŚŪŤĢ ÔÓÍŗÁŗÚŚŽˇ šŚšůÔŽŤÍŗŲŤŤ ÔÓŽůųŗŚÚ١ ÔūŤ ÔūÓ‚ŚšŚŪŤŤ ŤŮÔŻÚŗŪŤť Ů ŤŮÔÓŽŁÁÓ‚ŗŪŤŚž ūŚŗŽŁŪŻű šŗŪŪŻű Ť ÍÓŪÍūŚÚŪŻű žŗŮŮŤ‚Ó‚.
«ŗÍŽĢųŚŪŤŚ
“ŗÍŤž ÓŠūŗÁÓž, ÔūÓŲŚšůūŗ šůÔŽŤÍŗŲŤŤ ˇ‚ŽˇŚÚ١ šÓŮÚŗÚÓųŪÓ ÔūÓŮÚÓť ÚŚűŪÓŽÓ„ŤŚť ÓÔÚŤžŤÁŗŲŤŤ ūŗŠÓÚŻ űūŗŪŤŽŤýŗ, ŚŮŽŤ Ôūŗ‚ŤŽŁŪÓ ūŗÁÓŠūŗڣ١ ‚Ó ‚ŮŚű ŚŚ ŪĢŗŪŮŗű. —ŽŚšůŚÚ ÚŗÍśŚ ÓÚžŚÚŤÚŁ, ųÚÓ ÍūÓžŚ ÔūÓŲŚŮŮŗ šŚšůÔŽŤÍŗŲŤŤ ūŗŮŮžŗÚūŤ‚ŗĢÚ١ Ť ŤŪŻŚ ŮÔÓŮÓŠŻ żŰŰŚÍÚŤ‚ŪÓ„Ó űūŗŪŚŪŤˇ šŗŪŪŻű. őšŪŤž ŤÁ ÚŗÍŤű ŗŽŁÚŚūŪŗÚŤ‚ŪŻű ūŚÝŚŪŤť ˇ‚ŽˇŚÚ١ ůŮÚūŗŪŚŪŤŚ ÍÓÔŤť ÓšŤŪŗÍÓ‚Żű šŗŪŪŻű Ė ŮųŤÚŗŚÚ١, ųÚÓ żÚŗ ÔūÓŲŚšůūŗ ˇ‚ŽˇŚÚ١ ŠÓŽŚŚ żŰŰŚÍÚŤ‚ŪÓť, ųŚž ŪŗūŗýŤ‚ŗŪŤŚ ÍÓżŰŰŤŲŤŚŪÚŗ šŚšůÔŽŤÍŗŲŤŤ Ť ÍÓžÔūŚŮŮŤŤ šŗŪŪŻű. Ōūŗ‚šŗ ÚŗÍÓť ÔÓšűÓš ŪůśšŗŚÚ١ ‚ ÍŗūšŤŪŗŽŁŪÓž ‚ŪŚšūŚŪŤŤ ŪÓ‚Ó„Ó ÍÓžÔŽŚÍŮŗ ÚŚűŪŤųŚŮÍŤű ūŚÝŚŪŤť Ť ŤÁžŚŪŚŪŤˇ Ôūŗ‚ŤŽ ūŗŠÓÚŻ ÔūŤŽÓśŚŪŤť Ů ŗūűŤ‚ŤūůŚžÓť ŤŪŰÓūžŗŲŤŚť.